Terrain Hydrology: Part I
13 Jul 2021 - zach
Outline
- The problem
- The algorithm
- Premise
- Hydrology
- Cells and ridges
- Terrain tree
- The discovery
- References and citations
The problem
Terrain generation is a topic that I have always been interested in. I previously described the two broad categories of terrain generation in this previous article.
About 1.5 years ago I discovered a paper that described a very interesting ontogenetic approach. In this series of articles, I discuss my adventures implementing this algorithm in Python and C++, building on the previous work of GitHub user bmelaiths. My fork of this repository can be found at wattzhikang/terrainHydrology.
The paper can be found here: Terrain Generation Using Procedural Models Based on Hydrology, and I highly encourage you to read it.
The algorithm
Terrain is generated in the following steps:
Hydrology

The first step is to generate the river network itself. It begins by creating one or more river mouths, points along the coast (referred to in the paper as ‘Γ’) that drain into the sea.
Then the algorithm grows the river network from those points iteratively, until the network covers the entire land surface.
User input
Cells and ridges
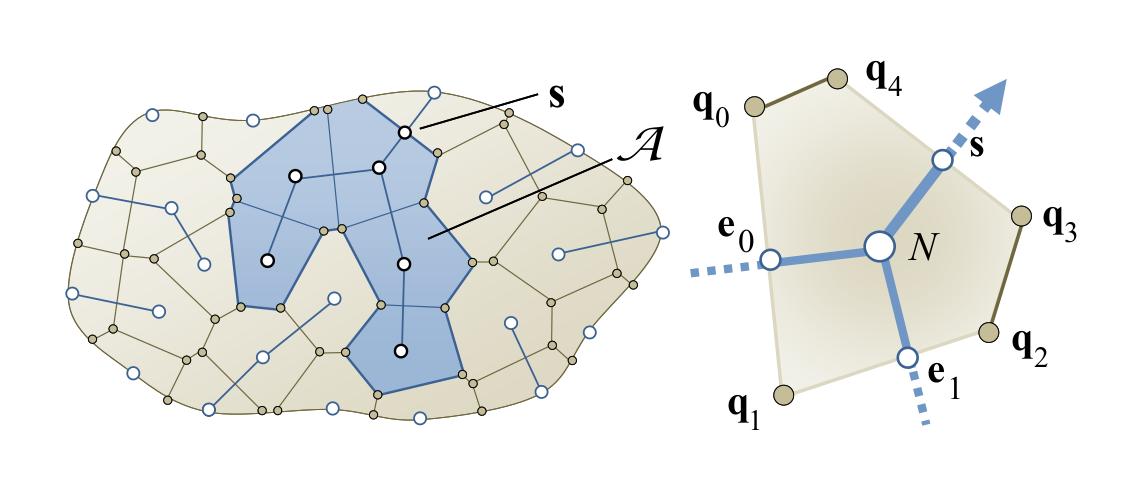
The next step is to partition the space into Voronoi cells. Cell edges that are not transected by a river are designated as valley ridges.
The algorithm then computes the flow of rivers by calculating the area of their watersheds, using the area of the Voronoi cells.
Terrain tree
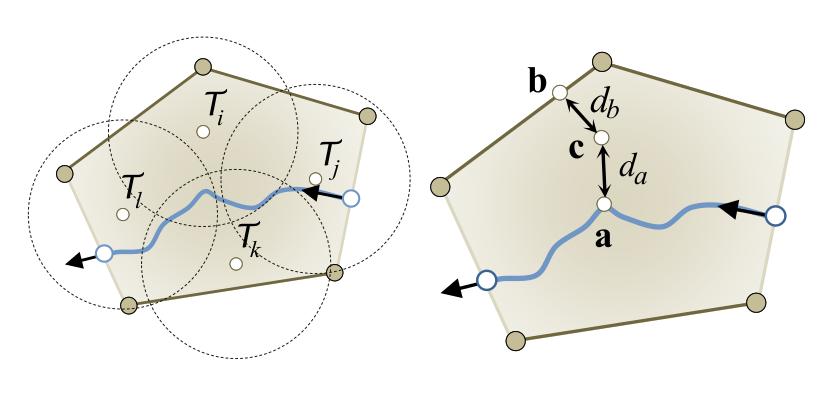
Finally, the land area is covered by points at a certain density. Each point has a certain elevation, computed from the elevation of the nearest river, the elevation of the nearest valley ridge, and the distance between them.
The discovery
When I first encountered the paper in 2020, I was fascinated by the results, but uncertain as to where to start. Burdened by existing projects, I moved on.
In December of 2020, I discovered that GitHub user bmelaiths had posted a partial implementation to GitHub. He had implemented most of the algorithm as a Jupyter notebook. Although many features were missing, and the results were not to scale, it was highly useful.
Over the next 8 months, I would transform the project, refactoring the data model, implementing features from the original paper, implementing features not discussed in the paper, and writing modules that accelerate the process by executing parts of the algorithm in parallel. This series of articles will document that process.
References and citations
- Geneveaux et al (2013), Terrain Generation Using Procedural Models Based on Hydrology
- Watt, Zachariah (2020), Fictional Digital Elevation Model